Output Summaries
IMDA collects and stores most important information and writes it to a presentation and a spreadsheet file entitled summary.pptx and summary.xlsx, respectively. The files are created using the Python libraries python-pptx and xlsxwriter. Both provide files which are compatible with Microsoft Powerpoint and Excel on Windows and LibreOffice on Linux devices.
Presentation File Summary
IMDA collects all plots generated and automatically generates a presentation file entitled summary.pptx for an immediate overview, quality check, first interpretations and for simplified comparison of multiple samples as well as planning further research steps.
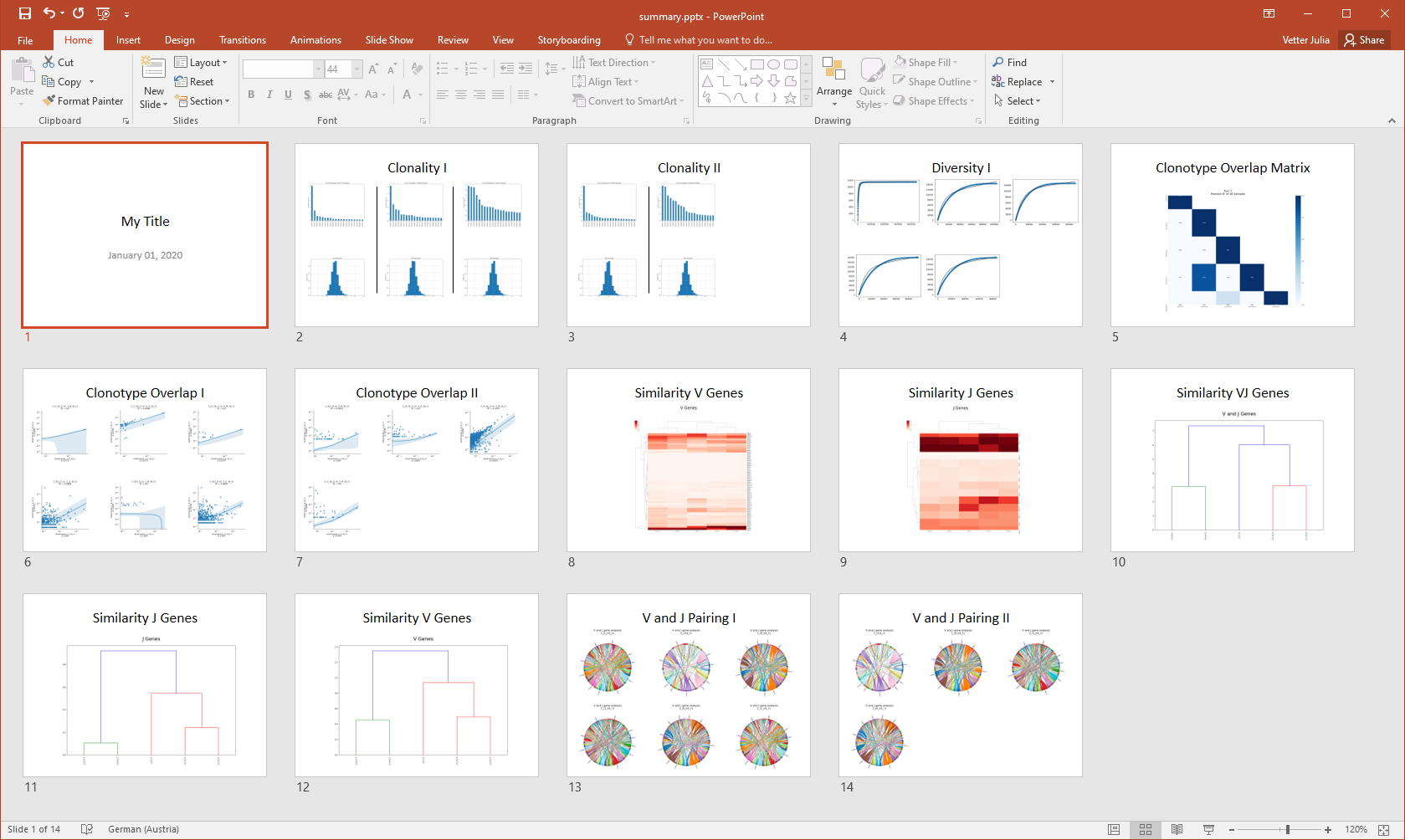
Figure 10: Summary output in presentation file format entitled summary.pptx
Spreadsheet File Summary
In addition to the presentation file, IMDA generates a spreadsheet file entitled summary.xlsx including all important and available numeric data:
- important sample information like barcodes and UMI definitions,
- read counts and read count development,
- alignment rates,
- clone counts,
- average CDR3 amino acid sequence length and standard deviation,
- diversity calculations including different diversity indices and curve parameter description,
- a clonotype overlap matrix with the calculated Pearson R² value for all samples,
- V, D, and J gene segment frequencies,
- counts of shared UMIs,
- and the used commands for the included open source software tools.
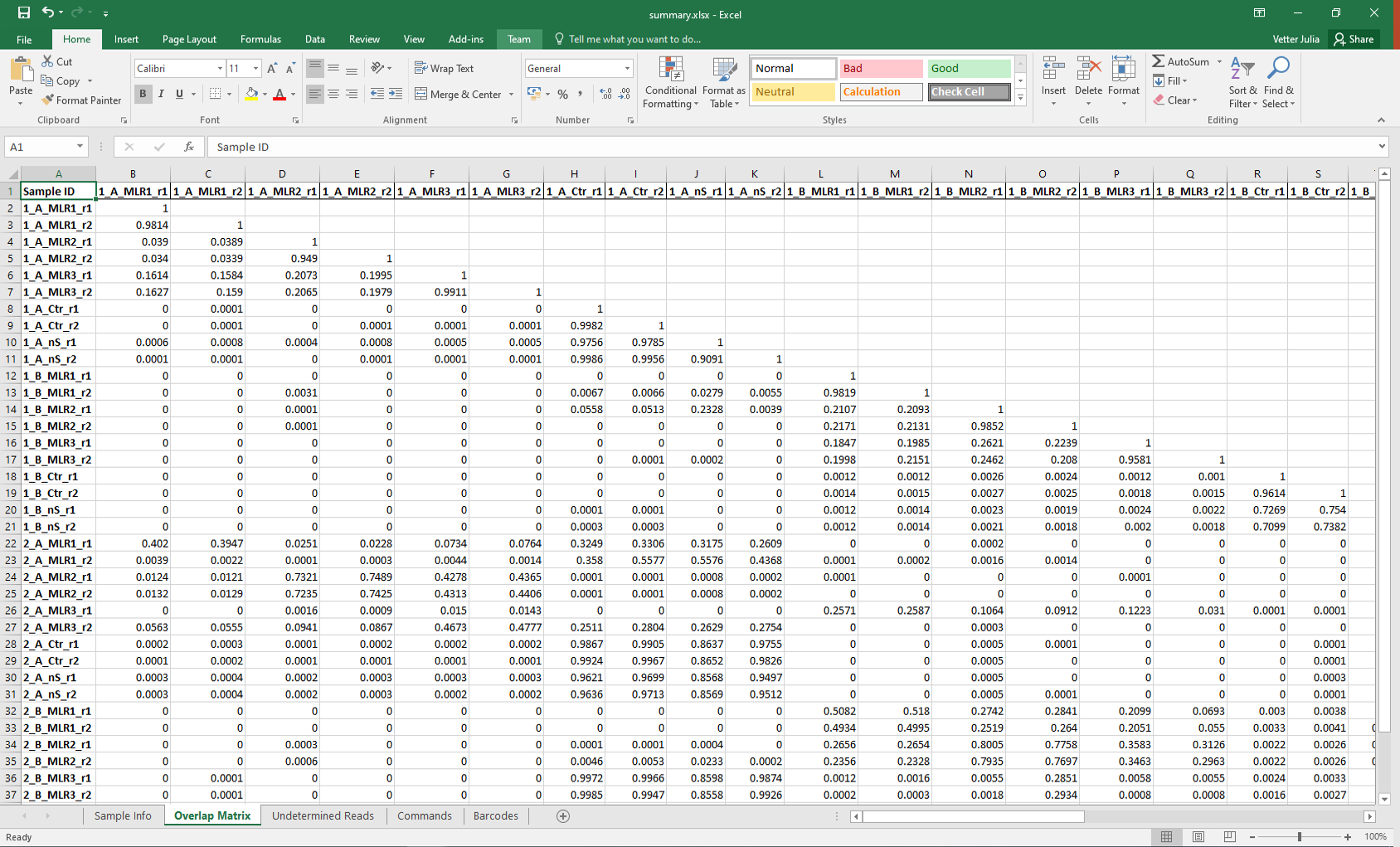
Figure 11: Summary output in spreadsheet file format entitled summary.xlsx
Machine Learning Output
IMDA provides further a tab-delimited file entitled ml.csv in format commonly used by machine learning (ML) frameworks. Additionally, IMDA provides the same file but with normalized values (ml_norm.csv) for mor accurate results. This file can be used for unsupervised ML algorithms (e.g. clustering) as well as for supervised learning algorithms (e.g. classification and regression algorithms). For performing supervised ML, an additional column defining the target variable has to be manually added. Tested ML algorithms are the implemented algorithms in the Python libraries scikit-learn (Figure 3) and keras as well as the ML framework for HeuristicLab.

Figure 12: Application of multiple machine learning algorithms on tab-delimited output
commonly used by ML frameworks